Correctness speaker average¶
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
|
|---|---|---|---|---|---|
Overall Score |
41.7% passed tests (5 passed / 7 failed). |
33.3% passed tests (4 passed / 8 failed). |
50.0% passed tests (6 passed / 6 failed). |
33.3% passed tests (4 passed / 8 failed). |
25.0% passed tests (3 passed / 9 failed). |
Class Proportion Mean Absolute Error¶
Data |
anger |
happiness |
neutral |
sadness |
||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
|
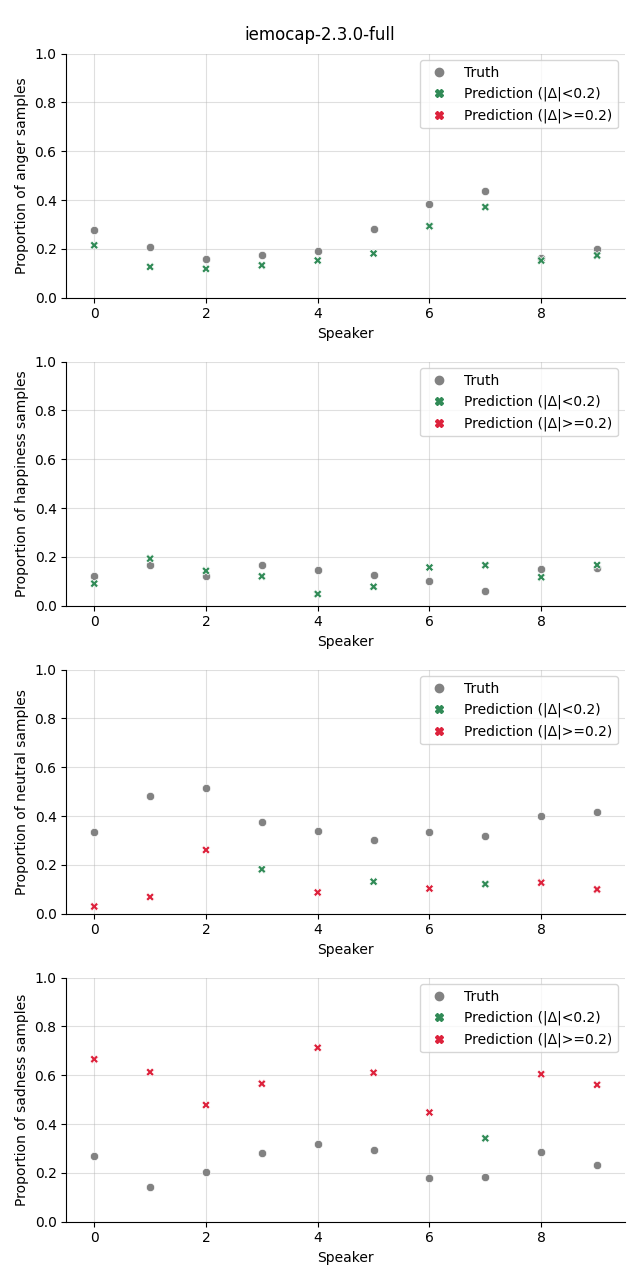
iemocap-2.3.0-full |
0.09 |
0.06 |
0.06 |
0.12 |
0.06 |
0.10 |
0.11 |
0.12 |
0.08 |
0.05 |
0.21 |
0.28 |
0.16 |
0.31 |
0.26 |
0.19 |
0.23 |
0.10 |
0.36 |
0.32 |
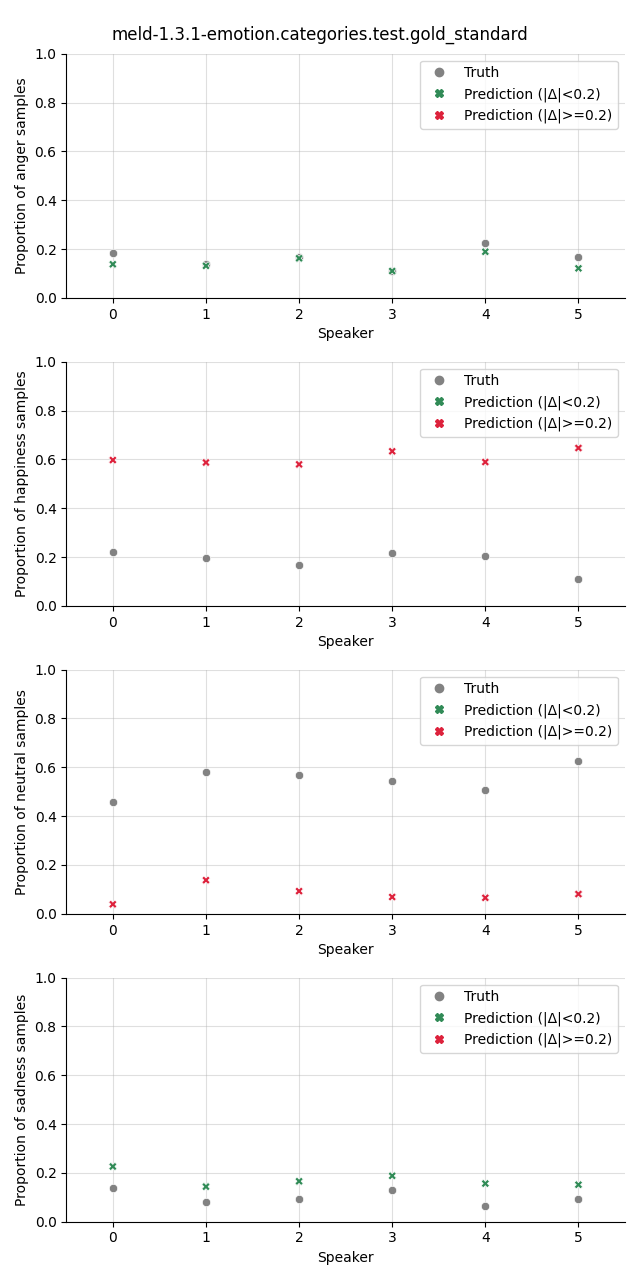
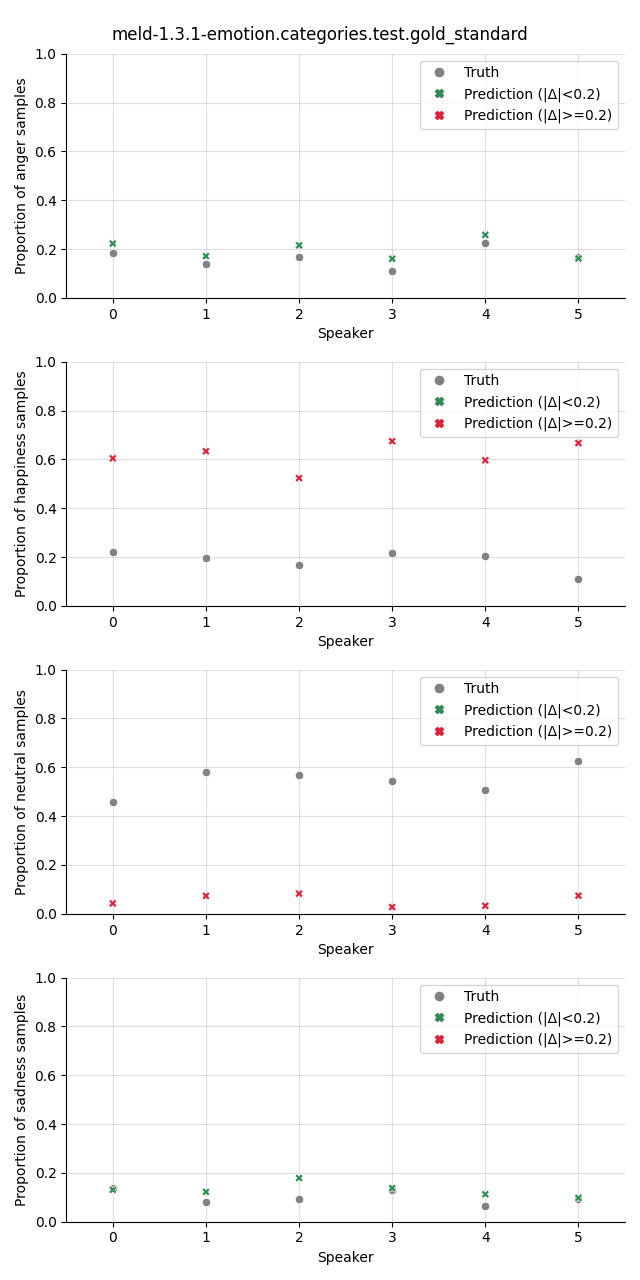
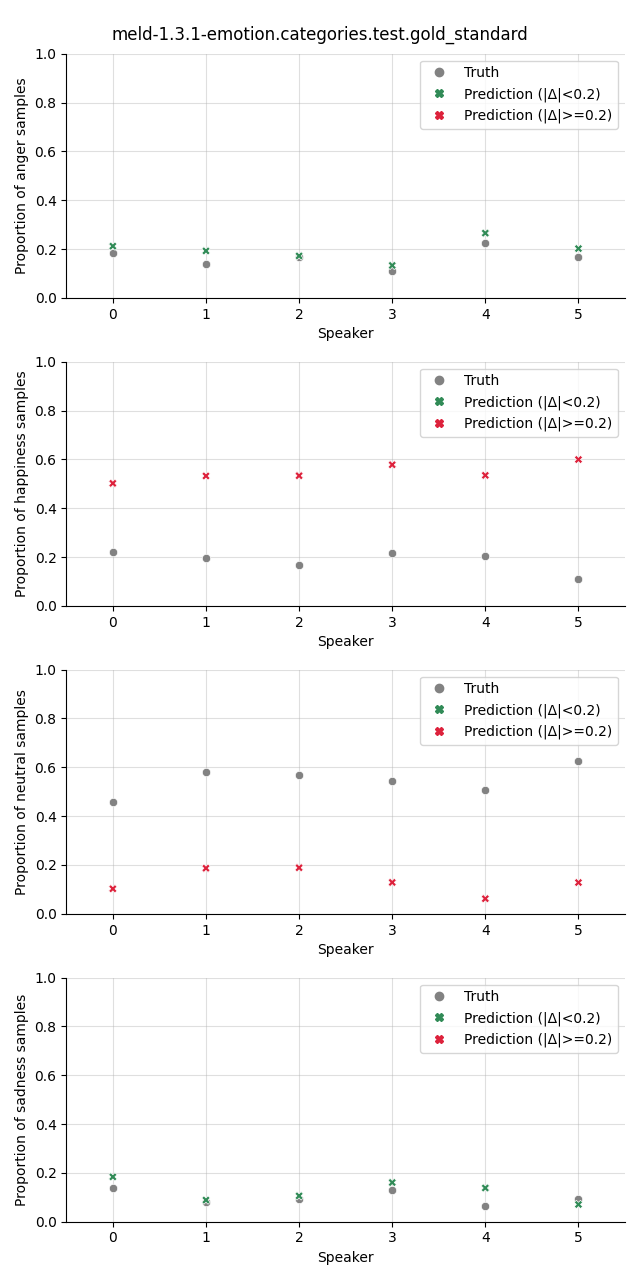
meld-1.3.1-emotion.categories.test.gold_standard |
0.02 |
0.03 |
0.03 |
0.02 |
0.21 |
0.42 |
0.43 |
0.36 |
0.34 |
0.19 |
0.47 |
0.49 |
0.42 |
0.50 |
0.46 |
0.07 |
0.03 |
0.03 |
0.15 |
0.06 |
msppodcast-2.6.0-emotion.categories.test-1.gold_standard |
0.05 |
0.10 |
0.07 |
0.07 |
0.15 |
0.11 |
0.12 |
0.07 |
0.10 |
0.10 |
0.23 |
0.26 |
0.16 |
0.17 |
0.16 |
0.09 |
0.05 |
0.05 |
0.09 |
0.13 |
mean |
0.05 |
0.06 |
0.05 |
0.07 |
0.14 |
0.21 |
0.22 |
0.18 |
0.17 |
0.11 |
0.30 |
0.34 |
0.25 |
0.33 |
0.29 |
0.12 |
0.10 |
0.06 |
0.20 |
0.17 |
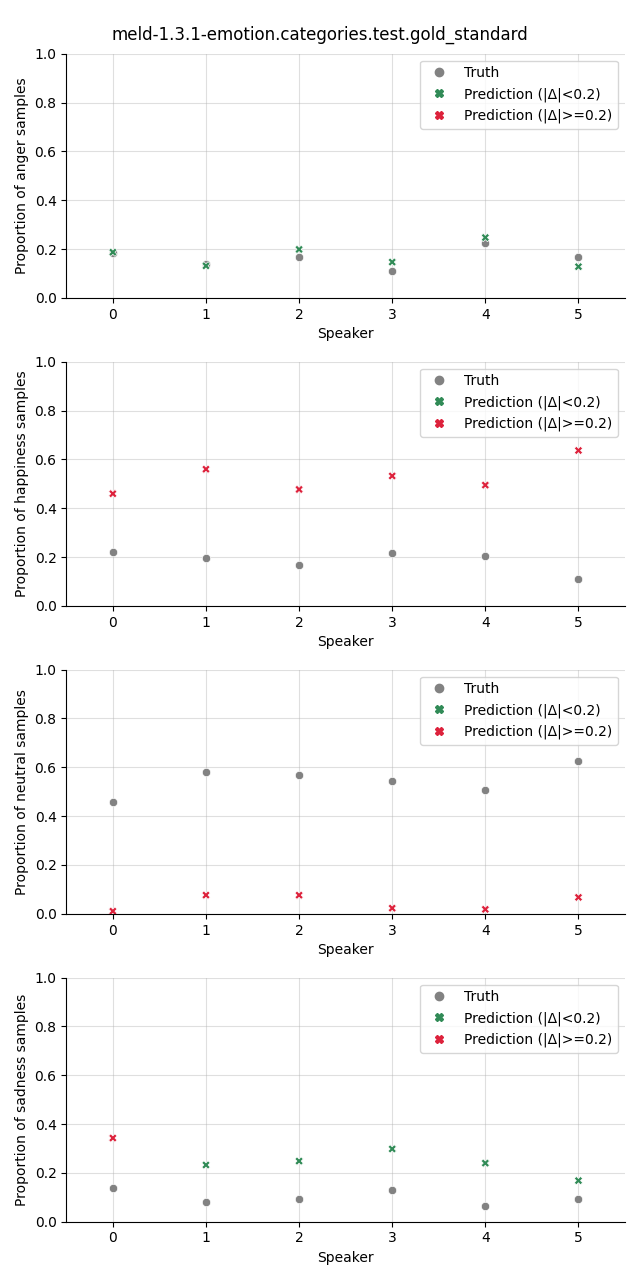
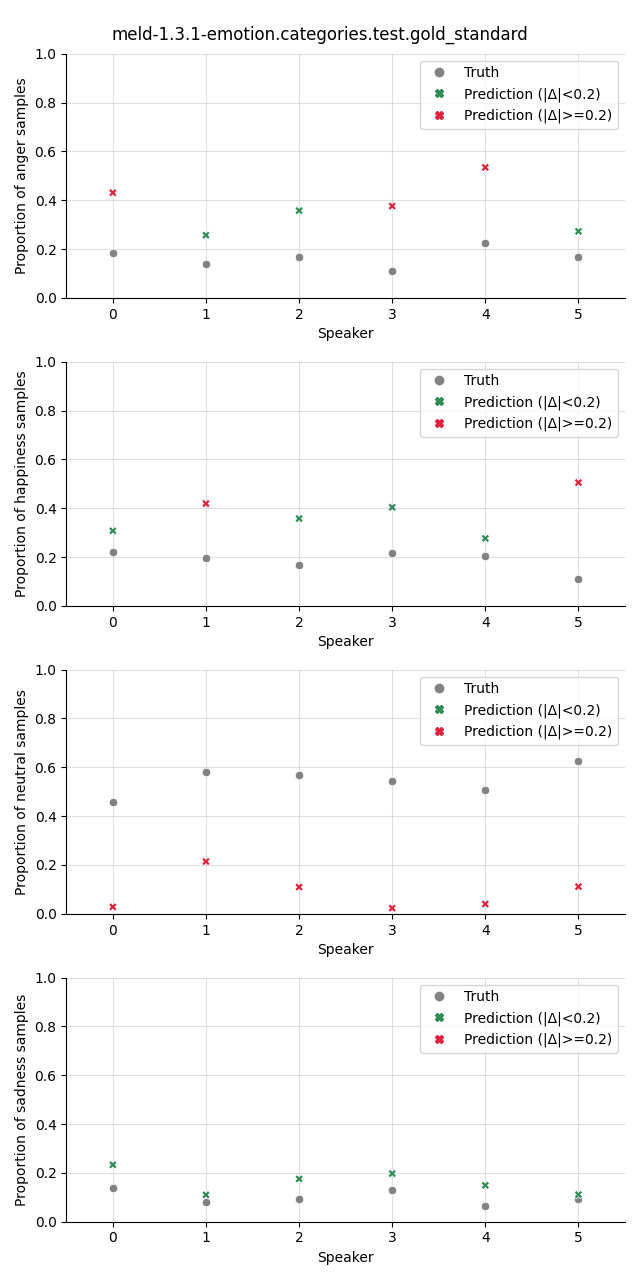
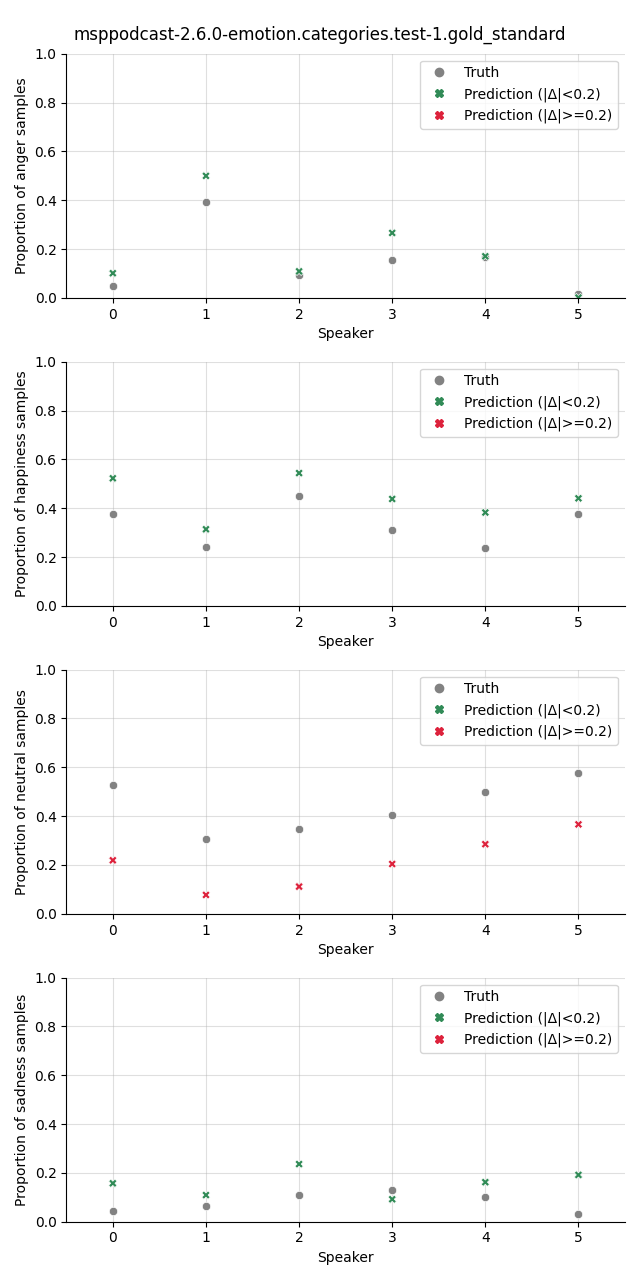
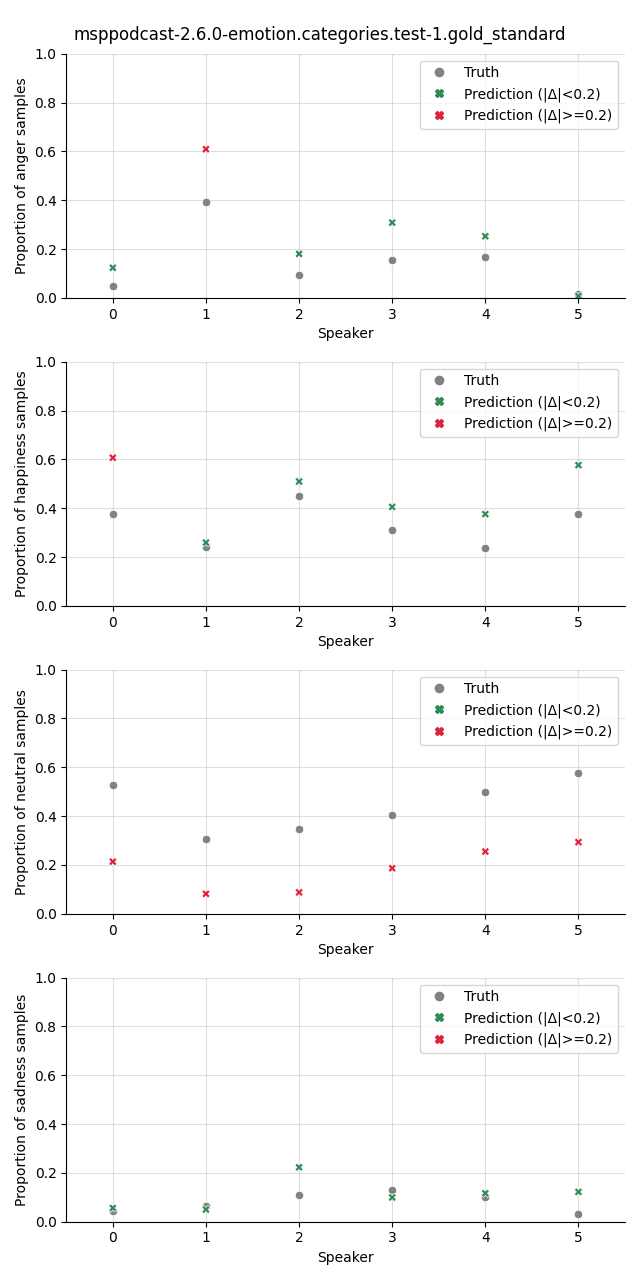
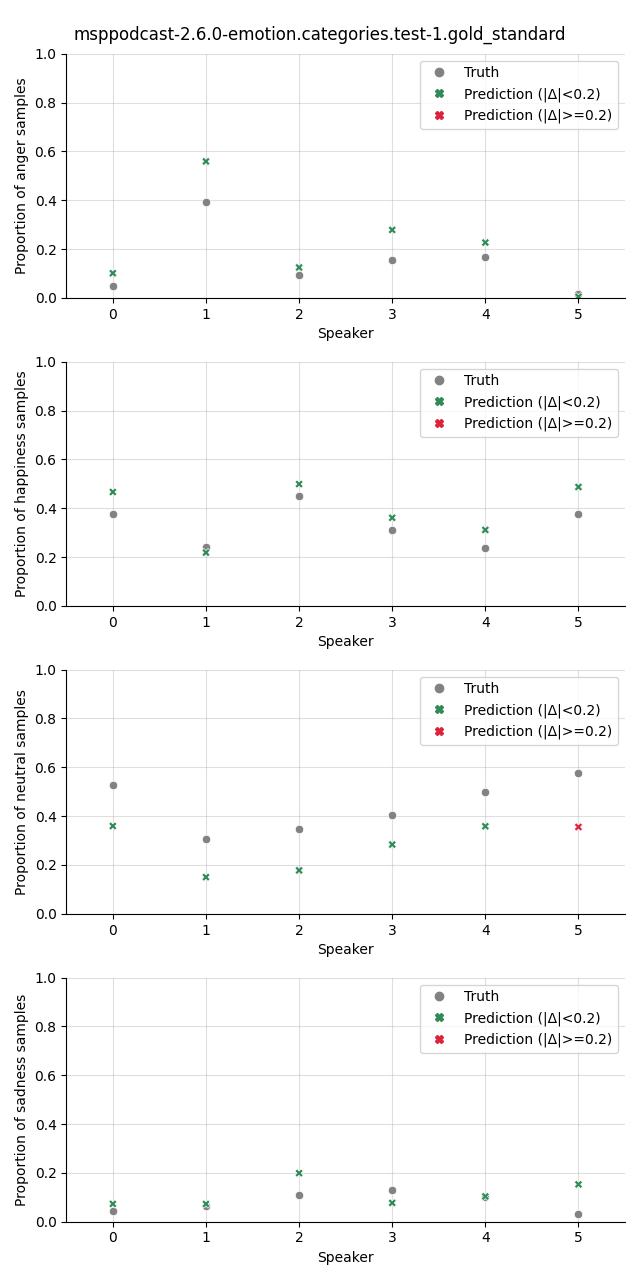
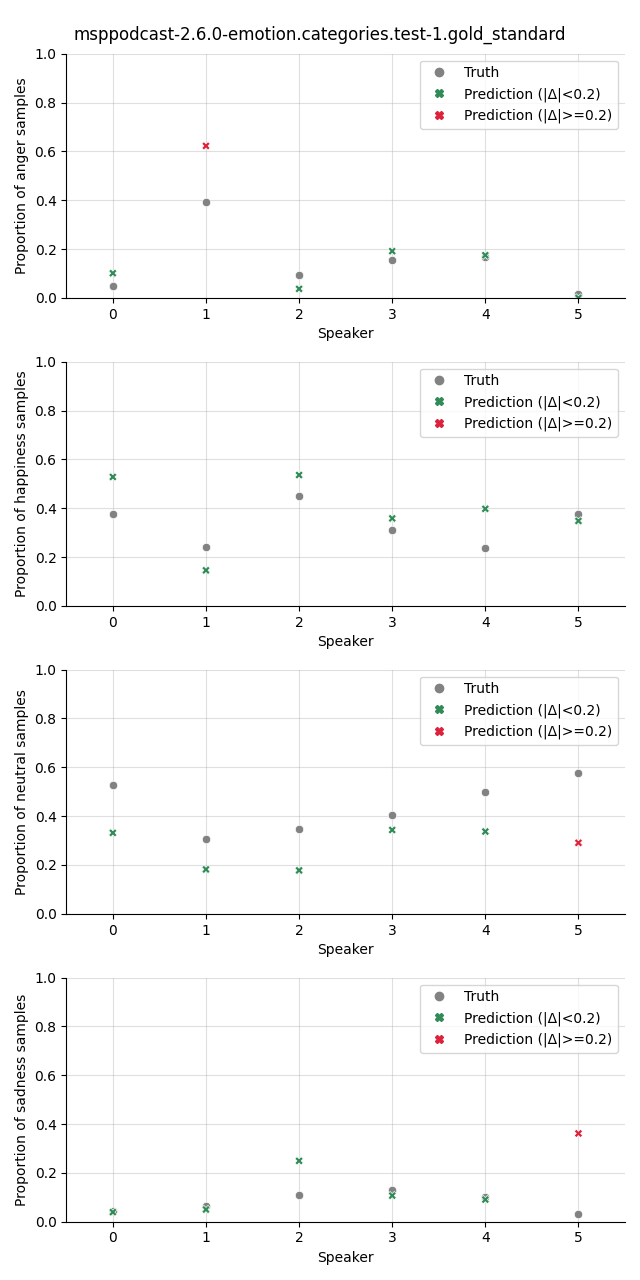
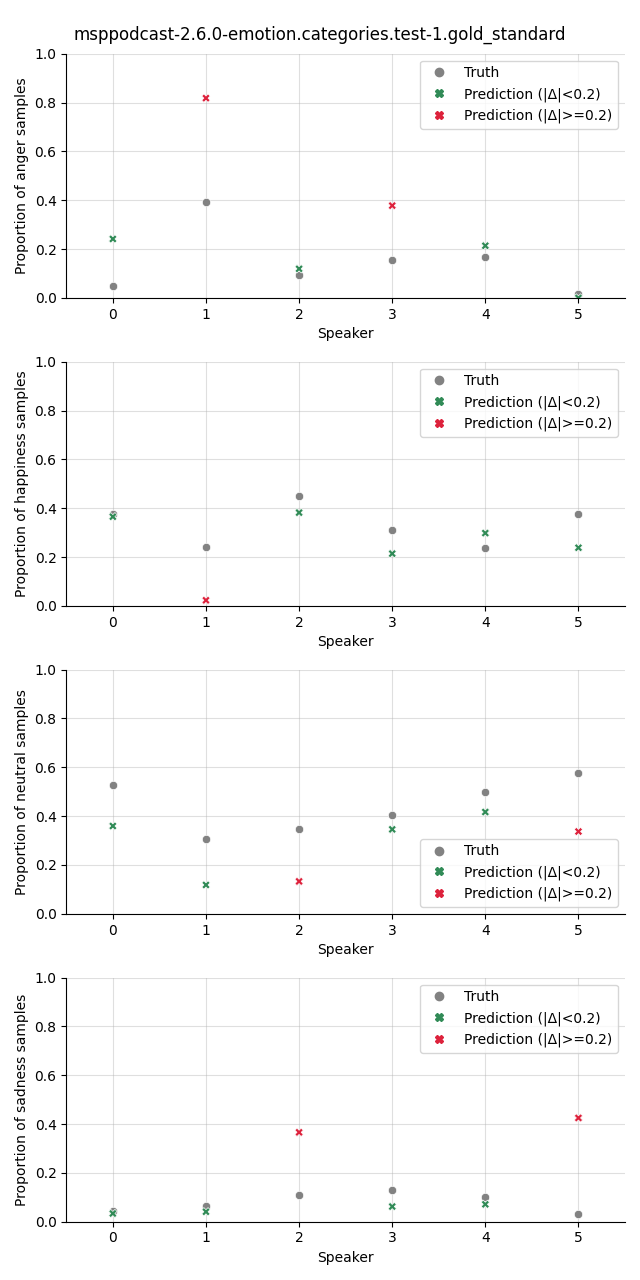
Visualization¶
The plot shows the proportion of the predicted samples for each class, as well as the true proportion of the class. We select a slightly higher threshold for the absolute error in the plots compared to the Class Proportion Difference test as we are interested in highlighting only big deviations here.
w2v2-b-cat |
w2v2-L-cat |
w2v2-L-robust-cat |
w2v2-L-vox-cat |
w2v2-L-xls-r-cat |
|---|---|---|---|---|
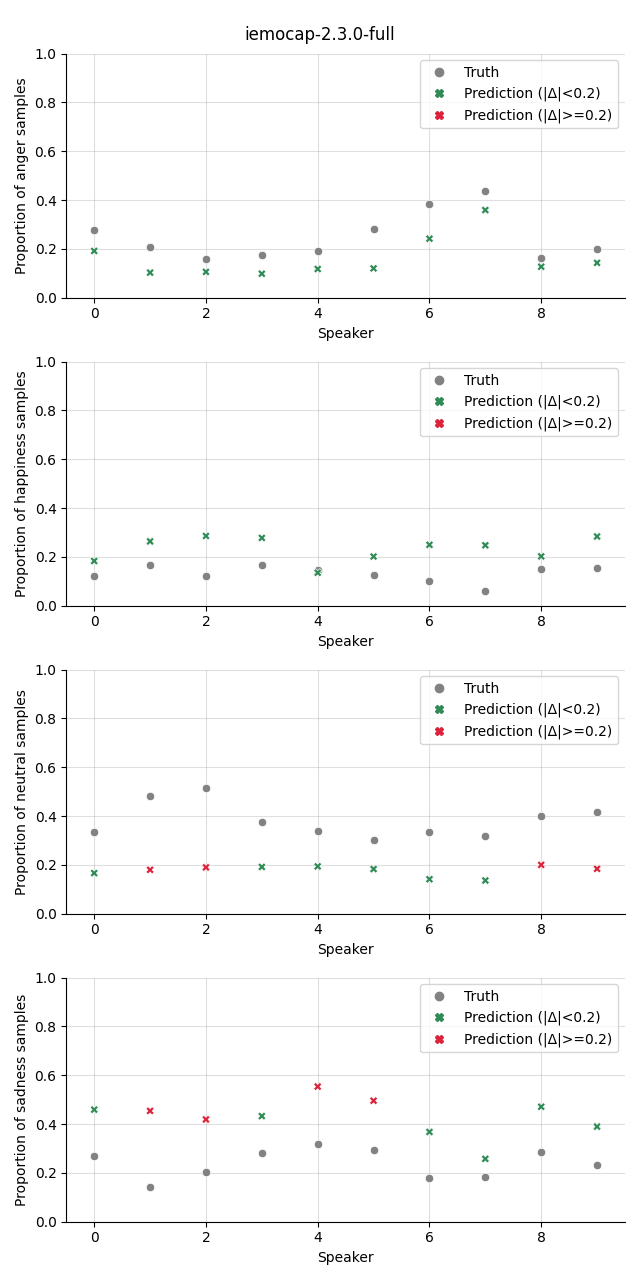
|
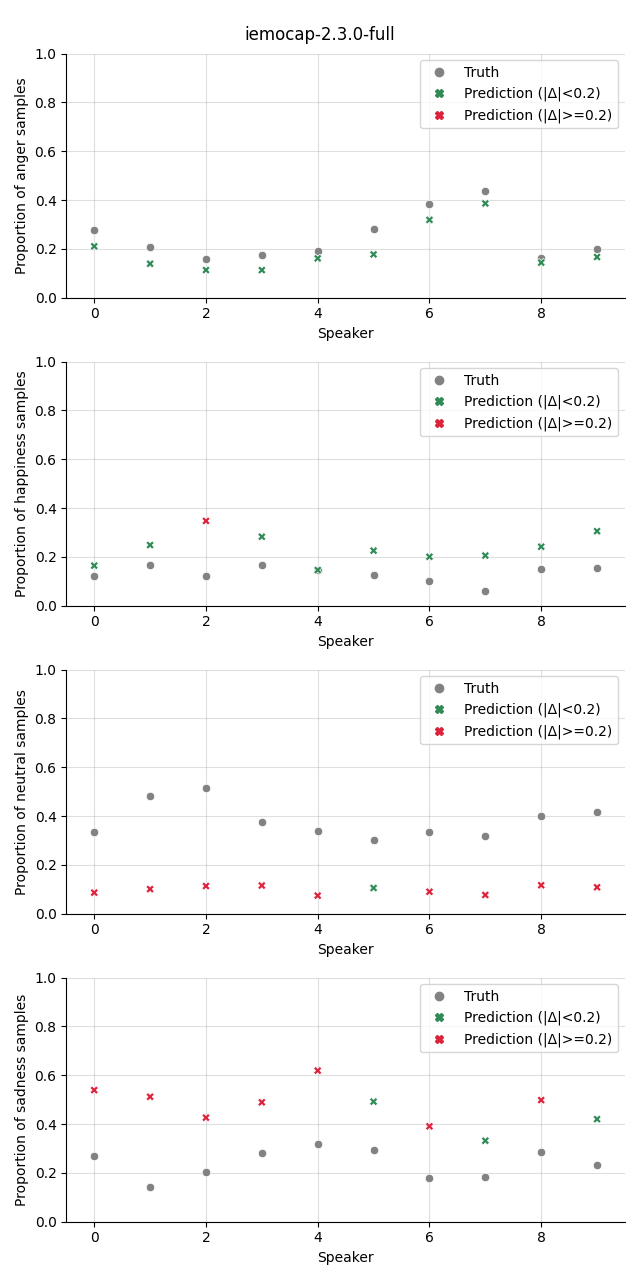
|
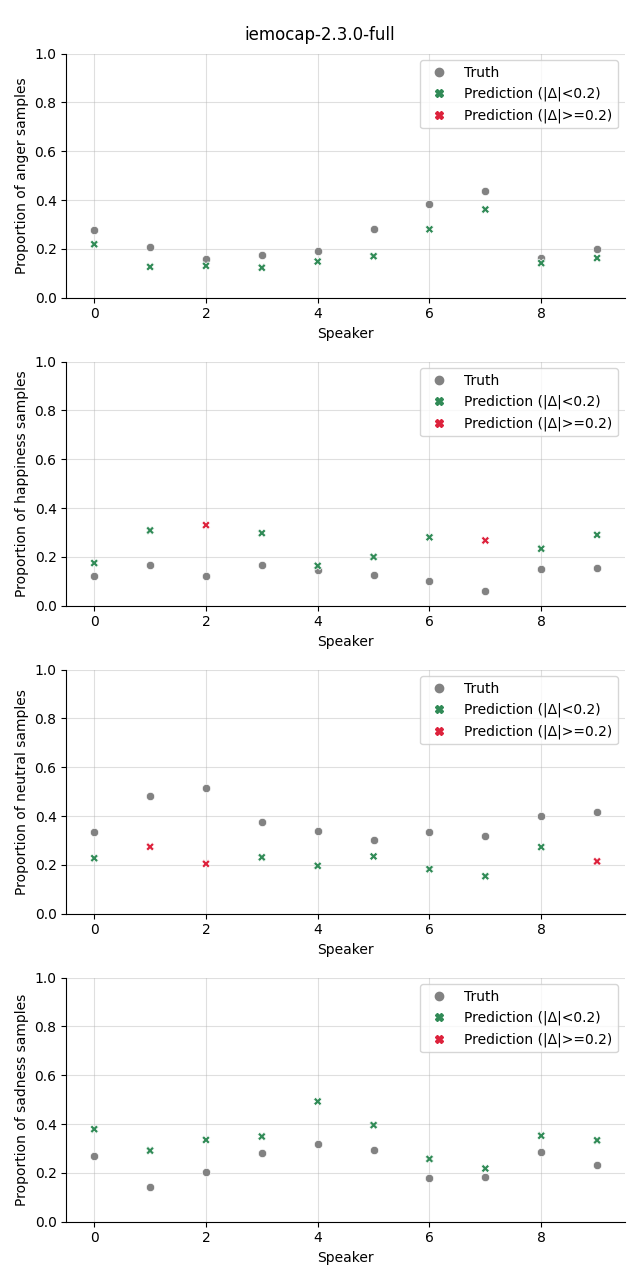
|
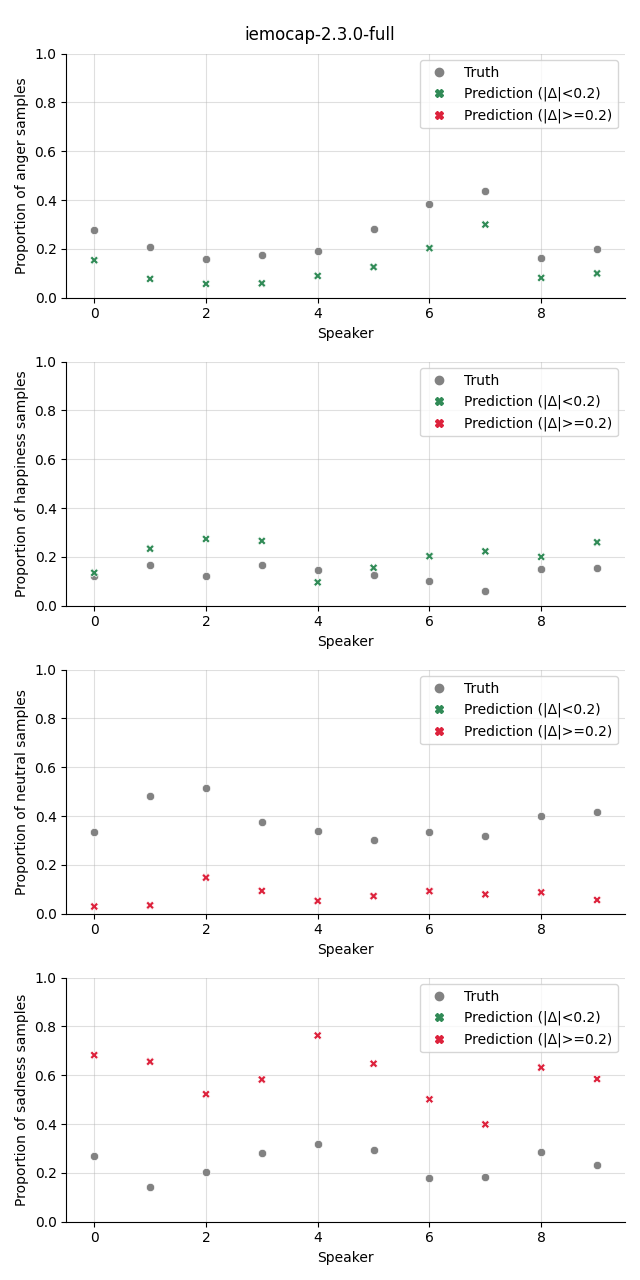
|
|
|
|
|
|
|
|
|
|
|
|